6장: 큰 그래프에 대한 stochastic 학습¶
만약 수백만, 수십억개의 노드들 또는 에지들을 갖는 큰 그래프인 경우에는 5장: 그래프 뉴럴 네트워크 학습하기 에서 소개한 그래프 전체를 사용한 학습을 적용하기 어려울 것이다. Hidden state 크기가 \(H\) 인 노드가 \(N\) 개인 그래프에 \(L\) -레이어의 graph convolutional network를 생각해보자. 중간 hidden 상태를 저장하는데 \((NLH)\) 메모리가 필요하고, \(N\) 이 큰 경우 GPU 하나의 용량을 훨씬 넘을 것이다.
이 절에서 모든 노드들의 피쳐를 GPU에 올려야할 필요가 없는 stochastic 미니-배치 학습을 수행하는 법을 알아본다.
이웃 샘플링(Neighborhood Sampling) 방법 개요¶
이웃 샘플링 방법은 일반적으로 다음과 같다. 각 gradient descent 단계마다, \(L-1\) 레이어의 최종 representation을 계산되어야 할 노드들의 미니 배치를 선택한다. 그 다음으로 \(L-1\) 레이어에서 그것들의 이웃 전체 또는 일부를 선택한다. 이 절차는 모델의 입력에 이를 때까지 반복된다. 이 반복 프로세스는 출력시작해서 거꾸로 입력까지의 의존성 그래프(dependency graph)를 생성하며, 이를 시각화하면 다음과 같다:
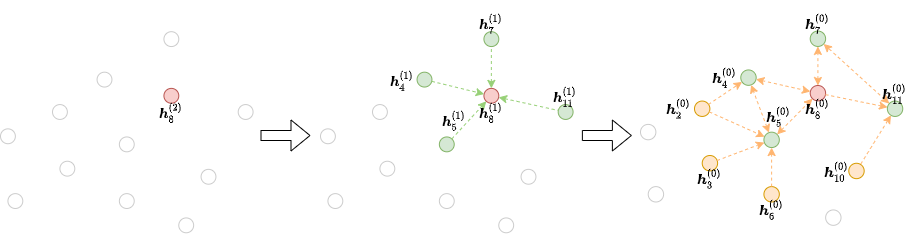
이를 사용하면, 큰 그래프에 대한 GNN 모델을 학습하는데 필요한 워크로드 및 연산 자원을 절약할 수 있다.
DGL은 이웃 샘플링을 사용한 GNN 학습을 위한 몇 가지 이웃 샘플러들과 파이프라인을 제공한다. 또한, 샘플링 전략을 커스터마이징하는 방법도 지원한다.
로드맵¶
이 장은 GNN은 stochastical하게 학습하는 여러 시나리오들로 시작한다.
이 후 절들에서는 새로운 샘플링 알고리즘들, 미니-배치 학습과 호환되는 새로운 GNN 모듈을 만들고자 하거나, 검증과 추론이 미니-배치에서 어떻게 수행되는지 이해하고 싶은 분들을 위한 보다 고급 토픽들을 다룬다.
마지막으로 이웃 샘플링을 구현하고 사용하는데 대한 성능 팁을 알아본다.