Node Classification¶
This tutorial shows how to train a multi-layer GraphSAGE for node classification on ogbn-arxiv provided by Open Graph Benchmark (OGB). The dataset contains around 170 thousand nodes and 1 million edges.
![]()
By the end of this tutorial, you will be able to
Train a GNN model for node classification on a single GPU with DGL’s neighbor sampling components.
Install DGL package¶
[1]:
# Install required packages.
import os
import torch
import numpy as np
os.environ['TORCH'] = torch.__version__
os.environ['DGLBACKEND'] = "pytorch"
# Install the CPU version. If you want to install CUDA version, please
# refer to https://www.dgl.ai/pages/start.html.
device = torch.device("cpu")
!pip install --pre dgl -f https://data.dgl.ai/wheels-test/repo.html
try:
import dgl
import dgl.graphbolt as gb
installed = True
except ImportError as error:
installed = False
print(error)
print("DGL installed!" if installed else "DGL not found!")
Looking in links: https://data.dgl.ai/wheels-test/repo.html
Requirement already satisfied: dgl in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages/dgl-2.0.0-py3.7-linux-x86_64.egg (2.0.0)
Requirement already satisfied: numpy>=1.14.0 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from dgl) (1.21.6)
Requirement already satisfied: scipy>=1.1.0 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from dgl) (1.7.3)
Requirement already satisfied: networkx>=2.1 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from dgl) (2.6.3)
Requirement already satisfied: requests>=2.19.0 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from dgl) (2.31.0)
Requirement already satisfied: tqdm in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from dgl) (4.66.1)
Requirement already satisfied: psutil>=5.8.0 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from dgl) (5.9.7)
Requirement already satisfied: torchdata>=0.5.0 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from dgl) (0.5.1)
Requirement already satisfied: charset-normalizer<4,>=2 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from requests>=2.19.0->dgl) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from requests>=2.19.0->dgl) (3.6)
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from requests>=2.19.0->dgl) (2.0.7)
Requirement already satisfied: certifi>=2017.4.17 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from requests>=2.19.0->dgl) (2023.11.17)
Requirement already satisfied: portalocker>=2.0.0 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from torchdata>=0.5.0->dgl) (2.7.0)
Requirement already satisfied: torch==1.13.1 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from torchdata>=0.5.0->dgl) (1.13.1)
Requirement already satisfied: typing-extensions in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from torch==1.13.1->torchdata>=0.5.0->dgl) (4.7.1)
Requirement already satisfied: nvidia-cuda-runtime-cu11==11.7.99 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from torch==1.13.1->torchdata>=0.5.0->dgl) (11.7.99)
Requirement already satisfied: nvidia-cudnn-cu11==8.5.0.96 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from torch==1.13.1->torchdata>=0.5.0->dgl) (8.5.0.96)
Requirement already satisfied: nvidia-cublas-cu11==11.10.3.66 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from torch==1.13.1->torchdata>=0.5.0->dgl) (11.10.3.66)
Requirement already satisfied: nvidia-cuda-nvrtc-cu11==11.7.99 in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from torch==1.13.1->torchdata>=0.5.0->dgl) (11.7.99)
Requirement already satisfied: setuptools in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from nvidia-cublas-cu11==11.10.3.66->torch==1.13.1->torchdata>=0.5.0->dgl) (68.0.0)
Requirement already satisfied: wheel in /home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/envs/2.0.x/lib/python3.7/site-packages (from nvidia-cublas-cu11==11.10.3.66->torch==1.13.1->torchdata>=0.5.0->dgl) (0.42.0)
WARNING:root:The OGB package is out of date. Your version is 1.2.4, while the latest version is 1.3.6.
DGL installed!
Loading Dataset¶
ogbn-arxiv is already prepared as BuiltinDataset in GraphBolt.
[2]:
dataset = gb.BuiltinDataset("ogbn-arxiv").load()
Downloading datasets/ogbn-arxiv.zip from https://data.dgl.ai/dataset/graphbolt/ogbn-arxiv.zip...
datasets/ogbn-arxiv.zip: 100%|██████████| 84.6M/84.6M [00:02<00:00, 36.1MB/s]
Extracting file to datasets
The dataset is already preprocessed.
Dataset consists of graph, feature and tasks. You can get the training-validation-test set from the tasks. Seed nodes and corresponding labels are already stored in each training-validation-test set. Other metadata such as number of classes are also stored in the tasks. In this dataset, there is only one task: node classification.
[3]:
graph = dataset.graph
feature = dataset.feature
train_set = dataset.tasks[0].train_set
valid_set = dataset.tasks[0].validation_set
test_set = dataset.tasks[0].test_set
task_name = dataset.tasks[0].metadata["name"]
num_classes = dataset.tasks[0].metadata["num_classes"]
print(f"Task: {task_name}. Number of classes: {num_classes}")
Task: node_classification. Number of classes: 40
How DGL Handles Computation Dependency¶¶
The computation dependency for message passing of a single node can be described as a series of message flow graphs (MFG).
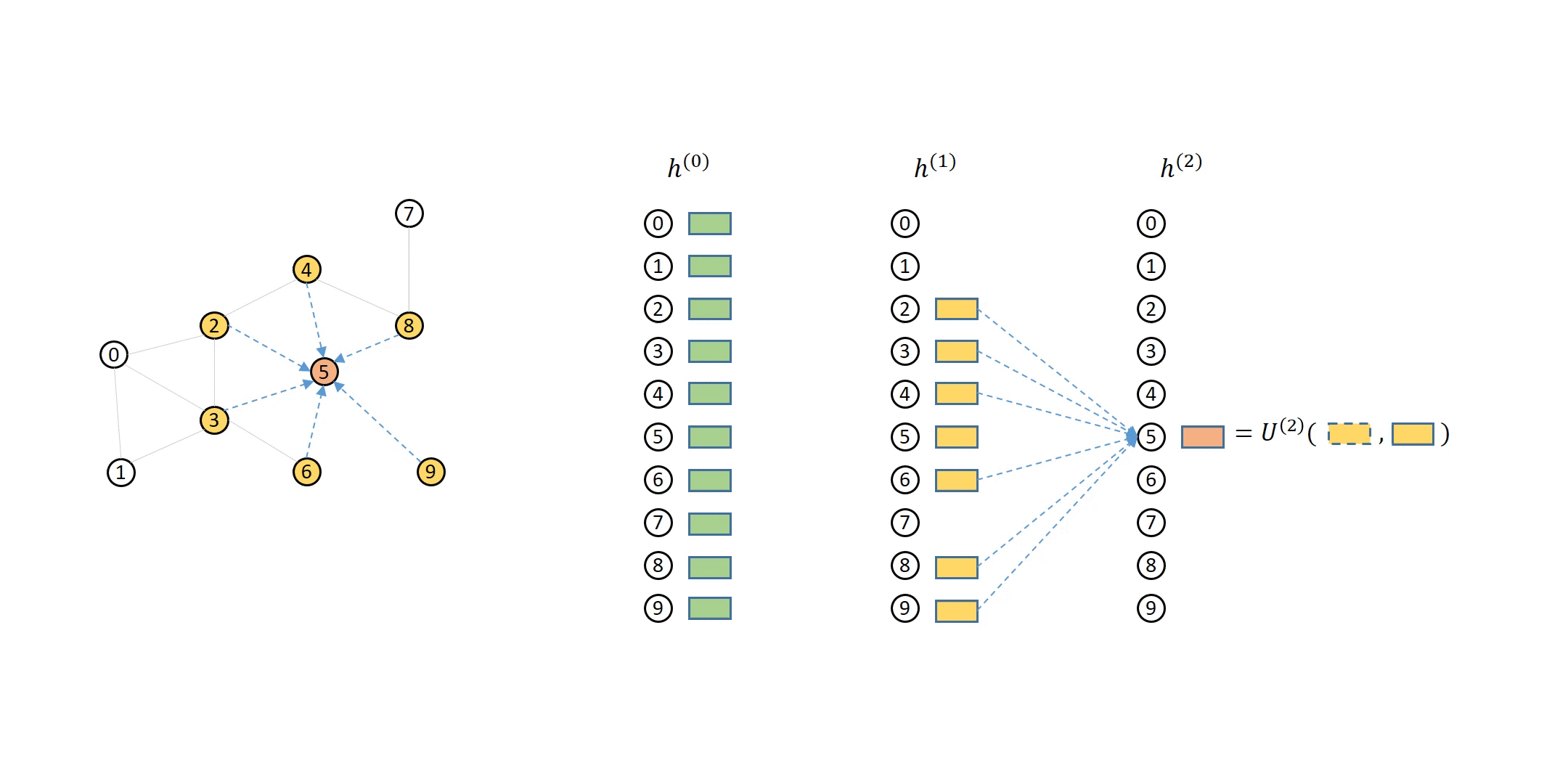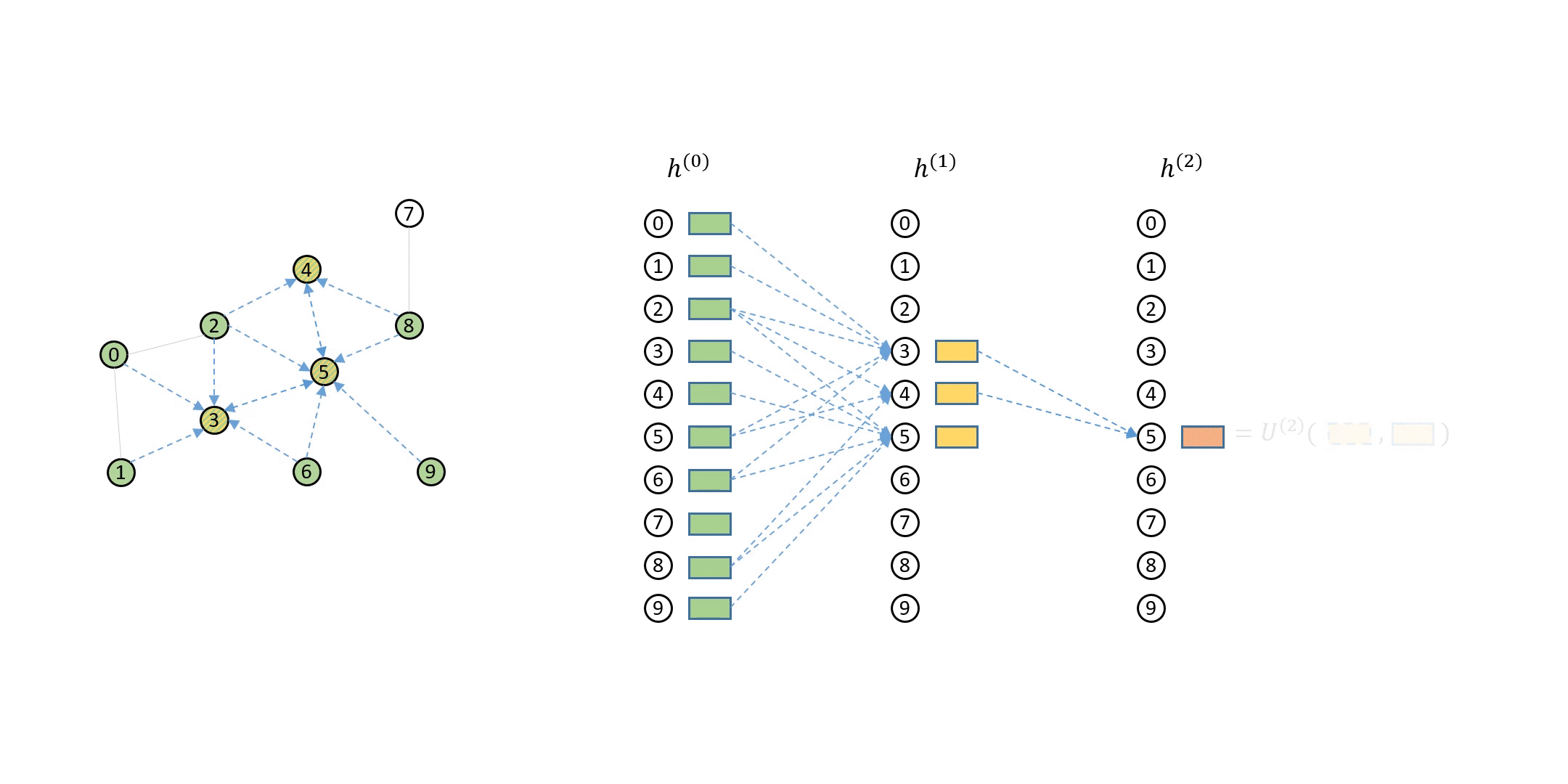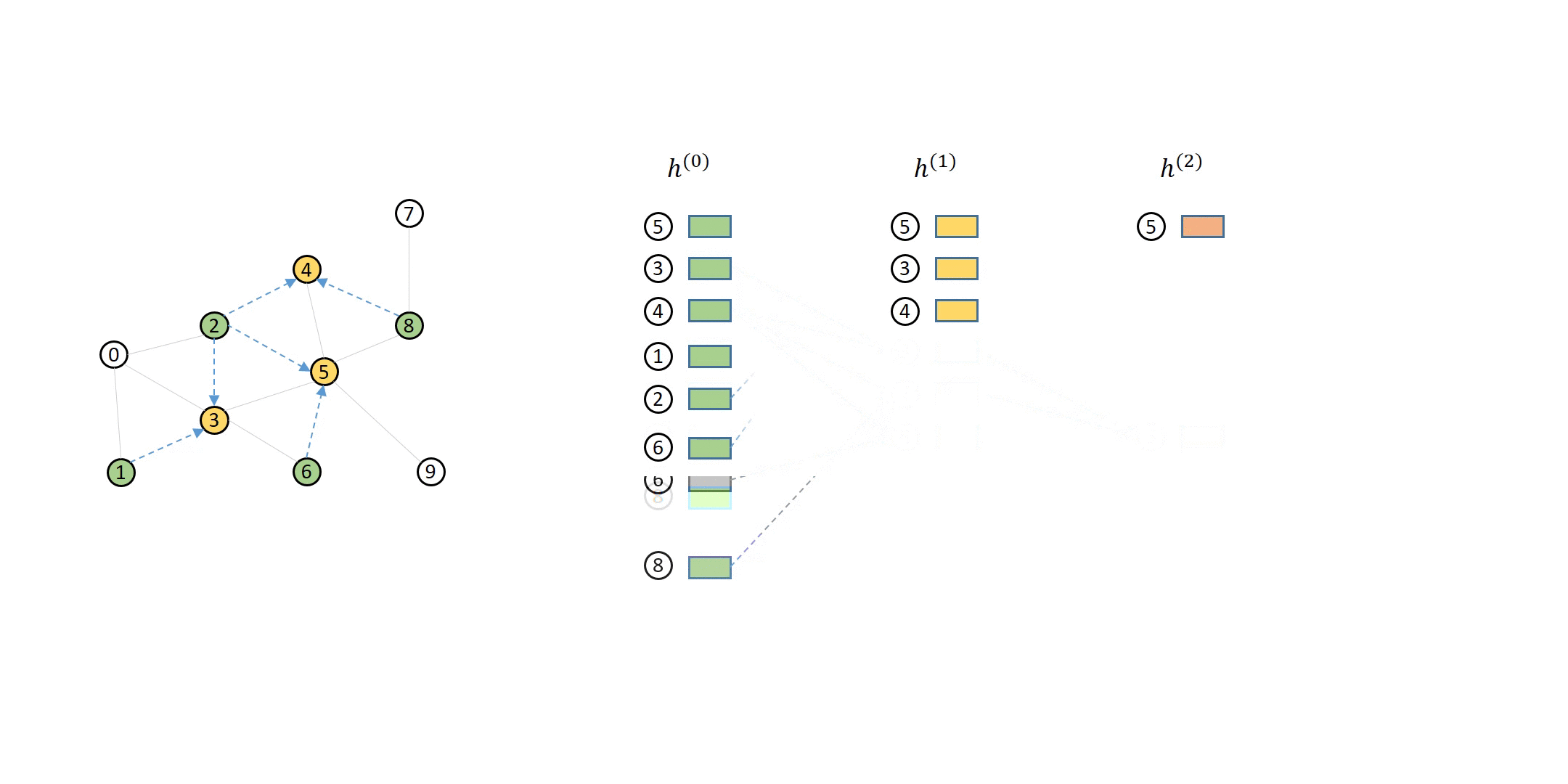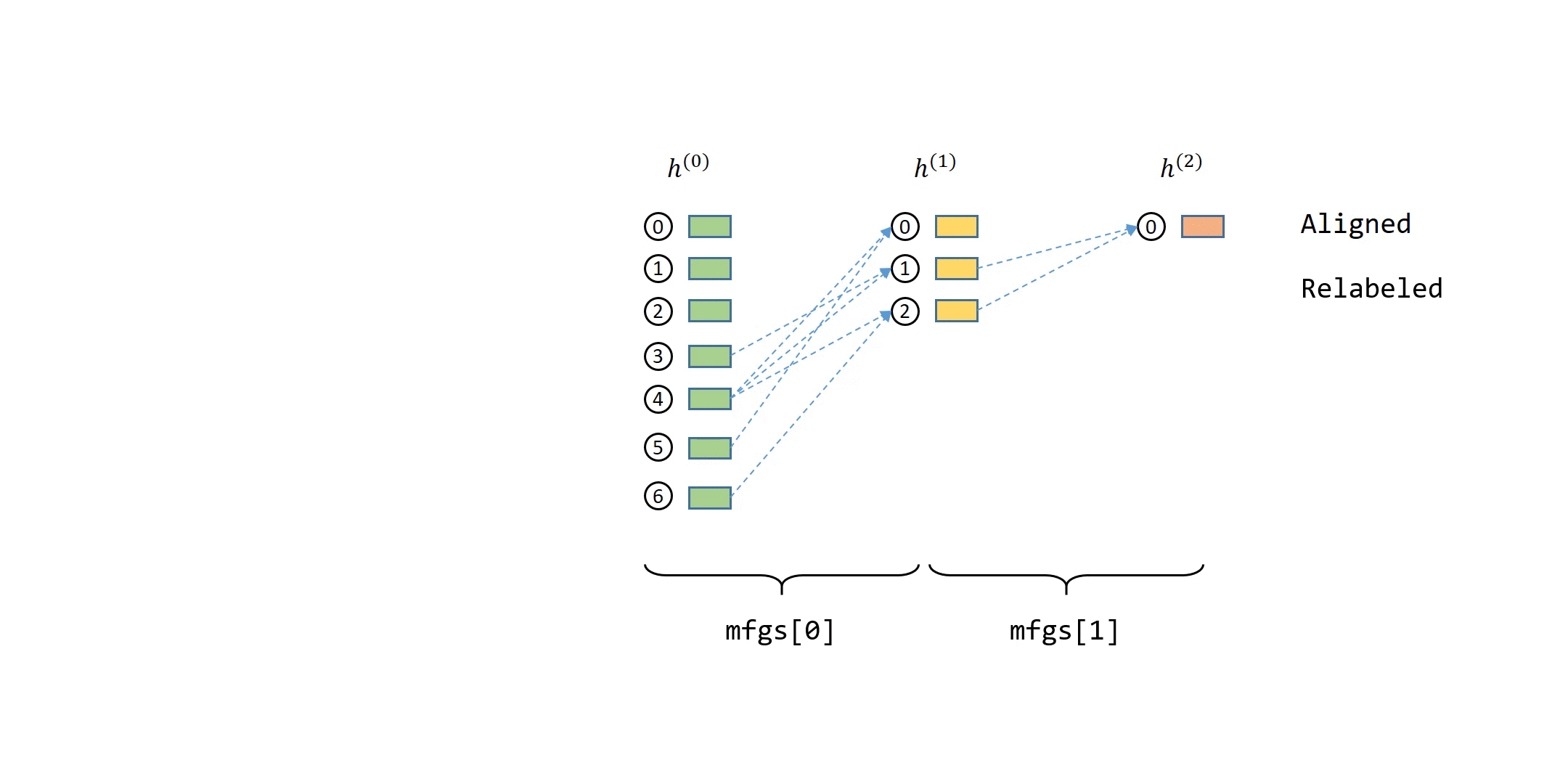
Defining Neighbor Sampler and Data Loader in DGL¶
DGL provides tools to iterate over the dataset in minibatches while generating the computation dependencies to compute their outputs with the MFGs above. For node classification, you can use dgl.graphbolt.DataLoader for iterating over the dataset. It accepts a data pipe that generates minibatches of nodes and their labels, sample neighbors for each node, and generate the computation dependencies in the form of MFGs. Feature fetching, block creation and copying to target device are also
supported. All these operations are split into separate stages in the data pipe, so that you can customize the data pipeline by inserting your own operations.
Let’s say that each node will gather messages from 4 neighbors on each layer. The code defining the data loader and neighbor sampler will look like the following.
[4]:
datapipe = gb.ItemSampler(train_set, batch_size=1024, shuffle=True)
datapipe = datapipe.sample_neighbor(graph, [4, 4])
datapipe = datapipe.fetch_feature(feature, node_feature_keys=["feat"])
datapipe = datapipe.copy_to(device)
train_dataloader = gb.DataLoader(datapipe, num_workers=0)
You can iterate over the data loader and a MiniBatch object is yielded.
[5]:
data = next(iter(train_dataloader))
print(data)
MiniBatch(seed_nodes=tensor([ 17584, 39933, 29125, ..., 99569, 79914, 142431]),
sampled_subgraphs=[SampledSubgraphImpl(sampled_csc=CSCFormatBase(indptr=tensor([ 0, 4, 8, ..., 6322, 6324, 6328]),
indices=tensor([3235, 1026, 2517, ..., 7254, 7255, 7256]),
),
original_row_node_ids=tensor([ 17584, 39933, 29125, ..., 29086, 108119, 129567]),
original_edge_ids=None,
original_column_node_ids=tensor([ 17584, 39933, 29125, ..., 9266, 151266, 104882]),
),
SampledSubgraphImpl(sampled_csc=CSCFormatBase(indptr=tensor([ 0, 4, 8, ..., 2239, 2240, 2244]),
indices=tensor([1024, 1025, 1026, ..., 3232, 3233, 3234]),
),
original_row_node_ids=tensor([ 17584, 39933, 29125, ..., 9266, 151266, 104882]),
original_edge_ids=None,
original_column_node_ids=tensor([ 17584, 39933, 29125, ..., 99569, 79914, 142431]),
)],
positive_node_pairs=None,
node_pairs_with_labels=None,
node_pairs=None,
node_features={'feat': tensor([[ 0.0484, 0.0207, -0.1518, ..., 0.0568, 0.0508, -0.1135],
[-0.1231, -0.1204, -0.0898, ..., 0.1959, -0.0484, -0.2502],
[-0.0554, -0.0221, -0.1482, ..., 0.1000, -0.2910, -0.0934],
...,
[-0.0695, -0.0313, -0.2291, ..., 0.1875, -0.0478, -0.0851],
[-0.0599, 0.0618, -0.2004, ..., -0.0053, -0.1062, -0.3105],
[-0.0581, 0.0386, -0.1483, ..., 0.0648, -0.0328, -0.1261]])},
negative_srcs=None,
negative_node_pairs=None,
negative_dsts=None,
labels=tensor([28, 28, 0, ..., 5, 26, 34]),
input_nodes=tensor([ 17584, 39933, 29125, ..., 29086, 108119, 129567]),
edge_features=[{},
{}],
compacted_node_pairs=None,
compacted_negative_srcs=None,
compacted_negative_dsts=None,
blocks=[Block(num_src_nodes=7257, num_dst_nodes=3235, num_edges=6328),
Block(num_src_nodes=3235, num_dst_nodes=1024, num_edges=2244)],
)
You can get the input node IDs from MFGs.
[6]:
mfgs = data.blocks
input_nodes = mfgs[0].srcdata[dgl.NID]
print(f"Input nodes: {input_nodes}.")
Input nodes: tensor([ 17584, 39933, 29125, ..., 29086, 108119, 129567]).
Defining Model¶
Let’s consider training a 2-layer GraphSAGE with neighbor sampling. The model can be written as follows:
[7]:
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn import SAGEConv
class Model(nn.Module):
def __init__(self, in_feats, h_feats, num_classes):
super(Model, self).__init__()
self.conv1 = SAGEConv(in_feats, h_feats, aggregator_type="mean")
self.conv2 = SAGEConv(h_feats, num_classes, aggregator_type="mean")
self.h_feats = h_feats
def forward(self, mfgs, x):
h = self.conv1(mfgs[0], x)
h = F.relu(h)
h = self.conv2(mfgs[1], h)
return h
in_size = feature.size("node", None, "feat")[0]
model = Model(in_size, 64, num_classes).to(device)
Defining Training Loop¶
The following initializes the model and defines the optimizer.
[8]:
opt = torch.optim.Adam(model.parameters())
When computing the validation score for model selection, usually you can also do neighbor sampling. To do that, you need to define another data loader.
[9]:
datapipe = gb.ItemSampler(valid_set, batch_size=1024, shuffle=False)
datapipe = datapipe.sample_neighbor(graph, [4, 4])
datapipe = datapipe.fetch_feature(feature, node_feature_keys=["feat"])
datapipe = datapipe.copy_to(device)
valid_dataloader = gb.DataLoader(datapipe, num_workers=0)
import sklearn.metrics
The following is a training loop that performs validation every epoch. It also saves the model with the best validation accuracy into a file.
[10]:
import tqdm
for epoch in range(10):
model.train()
with tqdm.tqdm(train_dataloader) as tq:
for step, data in enumerate(tq):
x = data.node_features["feat"]
labels = data.labels
predictions = model(data.blocks, x)
loss = F.cross_entropy(predictions, labels)
opt.zero_grad()
loss.backward()
opt.step()
accuracy = sklearn.metrics.accuracy_score(
labels.cpu().numpy(),
predictions.argmax(1).detach().cpu().numpy(),
)
tq.set_postfix(
{"loss": "%.03f" % loss.item(), "acc": "%.03f" % accuracy},
refresh=False,
)
model.eval()
predictions = []
labels = []
with tqdm.tqdm(valid_dataloader) as tq, torch.no_grad():
for data in tq:
x = data.node_features["feat"]
labels.append(data.labels.cpu().numpy())
predictions.append(model(data.blocks, x).argmax(1).cpu().numpy())
predictions = np.concatenate(predictions)
labels = np.concatenate(labels)
accuracy = sklearn.metrics.accuracy_score(labels, predictions)
print("Epoch {} Validation Accuracy {}".format(epoch, accuracy))
# Note that this tutorial do not train the whole model to the end.
break
89it [00:02, 42.28it/s, loss=2.304, acc=0.411]
30it [00:00, 89.64it/s]
Epoch 0 Validation Accuracy 0.3930333232658814
Conclusion¶
In this tutorial, you have learned how to train a multi-layer GraphSAGE with neighbor sampling.