Performance Benchmarks¶
Integrated Benchmarks¶
DGL continuously evaluates the speed of its core APIs, kernels as well as the training speed of the state-of-the-art GNN models. The benchmark code is available at the main repository. They are triggered for every nightly-built version and the results are published to https://asv.dgl.ai/.
v0.6 Benchmarks¶
To understand the performance gain of DGL v0.6, we re-evaluated it on the v0.5 benchmarks plus some new ones for graph classification tasks against the updated baselines. The results are available in a standalone repository.
v0.5 Benchmarks¶
Check out our paper Deep Graph Library: A Graph-Centric, Highly-Performant Package for Graph Neural Networks.
v0.4.3 Benchmarks¶
Microbenchmark on speed and memory usage: While leaving tensor and autograd functions to backend frameworks (e.g. PyTorch, MXNet, and TensorFlow), DGL aggressively optimizes storage and computation with its own kernels. Here’s a comparison to another popular package – PyTorch Geometric (PyG). The short story is that raw speed is similar, but DGL has much better memory management.
Dataset |
Model |
Accuracy |
Time |
Memory |
||
|---|---|---|---|---|---|---|
PyG |
DGL |
PyG |
DGL |
|||
Cora |
GCN |
81.31 ± 0.88 |
0.478 |
0.666 |
1.1 |
1.1 |
GAT |
83.98 ± 0.52 |
1.608 |
1.399 |
1.2 |
1.1 |
|
CiteSeer |
GCN |
70.98 ± 0.68 |
0.490 |
0.674 |
1.1 |
1.1 |
GAT |
69.96 ± 0.53 |
1.606 |
1.399 |
1.3 |
1.1 |
|
PubMed |
GCN |
79.00 ± 0.41 |
0.491 |
0.690 |
1.1 |
1.1 |
GAT |
77.65 ± 0.32 |
1.946 |
1.393 |
1.6 |
1.1 |
|
GCN |
93.46 ± 0.06 |
OOM |
28.6 |
OOM |
11.7 |
|
Reddit-S |
GCN |
N/A |
29.12 |
9.44 |
15.7 |
3.6 |
Table: Training time(in seconds) for 200 epochs and memory consumption(GB)
Here is another comparison of DGL on TensorFlow backend with other TF-based GNN tools (training time in seconds for one epoch):
Dateset |
Model |
DGL |
GraphNet |
tf_geometric |
|---|---|---|---|---|
Core |
GCN |
0.0148 |
0.0152 |
0.0192 |
GCN |
0.1095 |
OOM |
OOM |
|
PubMed |
GCN |
0.0156 |
0.0553 |
0.0185 |
PPI |
GCN |
0.09 |
0.16 |
0.21 |
Cora |
GAT |
0.0442 |
n/a |
0.058 |
PPI |
GAT |
0.398 |
n/a |
0.752 |
High memory utilization allows DGL to push the limit of single-GPU performance, as seen in below images.


Scalability: DGL has fully leveraged multiple GPUs in both one machine and clusters for increasing training speed, and has better performance than alternatives, as seen in below images.


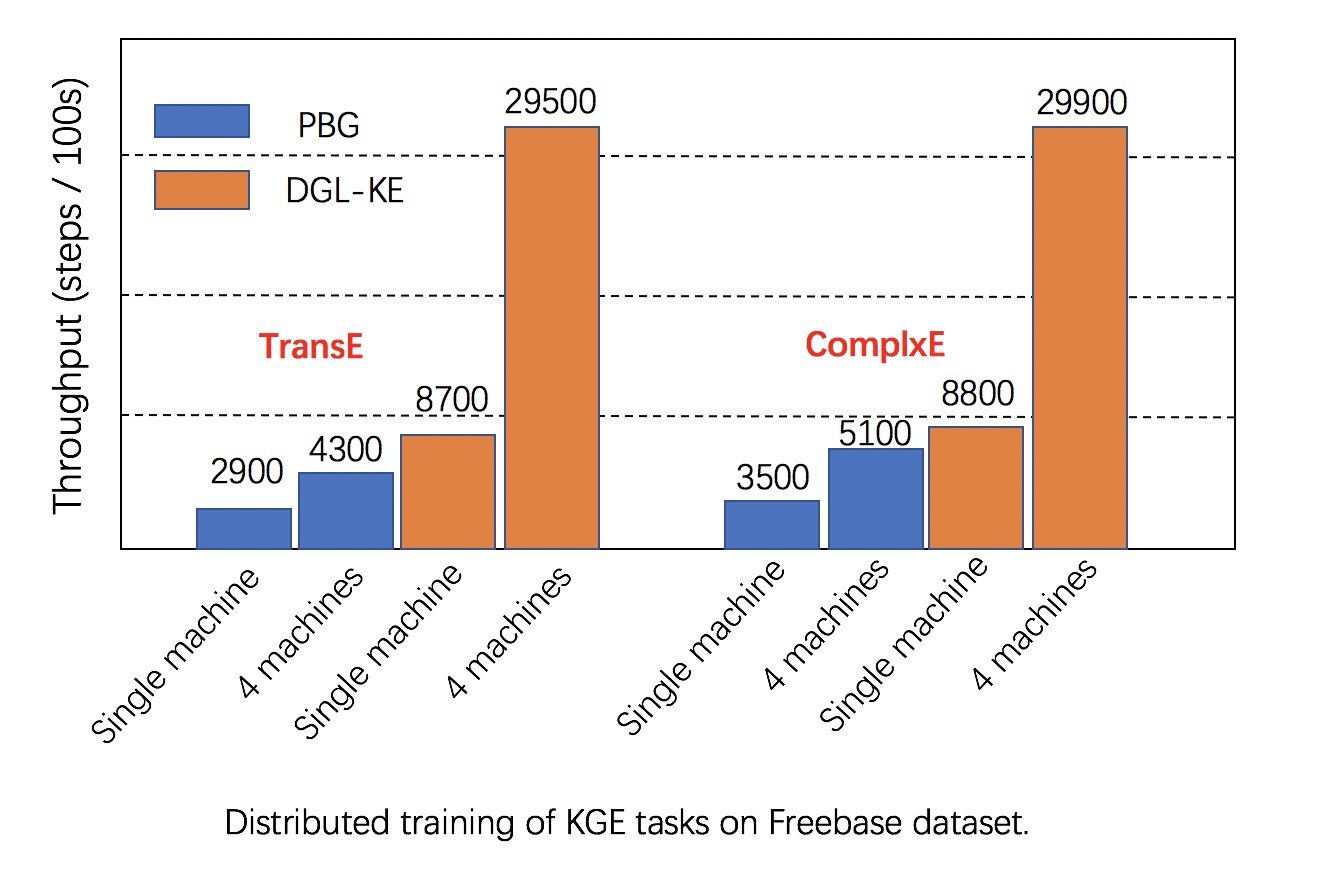
Further reading: Detailed comparison of DGL and other alternatives can be found [here](https://arxiv.org/abs/1909.01315).