6.6 큰 그래프들에 대핸 정확한 오프라인 추론¶
GPU를 사용해서 GNN을 학습하는데 메모리와 걸리는 시간을 줄이기 위해서 서브 샘플링과 이웃 샘플링이 모두 사용된다. 추론을 수행할 때 보통은 샘플링으로 발생할 수 있는 임의성을 제거하기 위해서 전체 이웃들에 대해서 aggretate하는 것이 더 좋다. 하지만, GPU 메모리 제약이나, CPU의 느린 속도 때문에 전체 그래프에 대한 forward propagagtion을 수행하는 것은 쉽지 않다. 이 절은 미니배치와 이웃 샘플링을 통해서 제한적인 GPU를 사용한 전체 그래프 forward propagation의 방법을 소개한다.
추론 알고리즘은 학습 알고리즘과는 다른데, 추론 알고리즘은 첫번째 레이어부터 시작해서 각 레이이별로 모든 노드의 representation들을 계산해야하기 때문이다. 특히, 특정 레이어의 경우에 우리는 미니배치의 모든 노드들에 대해서 이 레이어의 출력 representation을 계산해야한다. 그 결과, 추론 알고리즘은 모든 레이어들 iterate하는 outer 룹과 노들들의 미니배치를 iterate하는 inner 룹을 갖는다. 반면, 학습 알고리즘은 노드들의 미니배치를 iterate하는 outer 룹과, 이웃 샘플링과 메시지 전달을 위한 레이어들을 iterate하는 inner 룹을 갖는다.
아래 애니매이션은 이 연산이 어떻게 일어나는지를 보여주고 있다 (각 레이어에 대해서 첫 3개의 미니배치만 표현되고 있음을 주의하자)
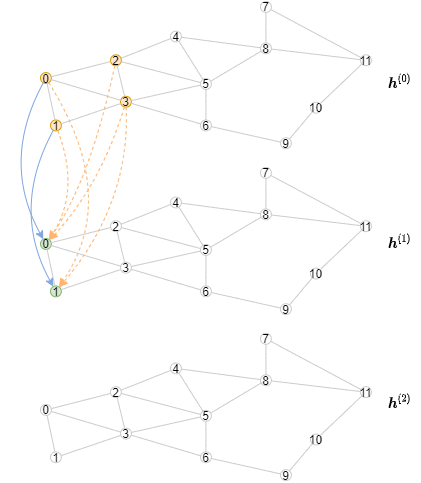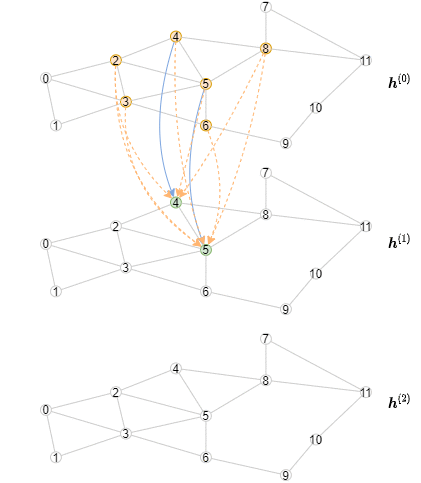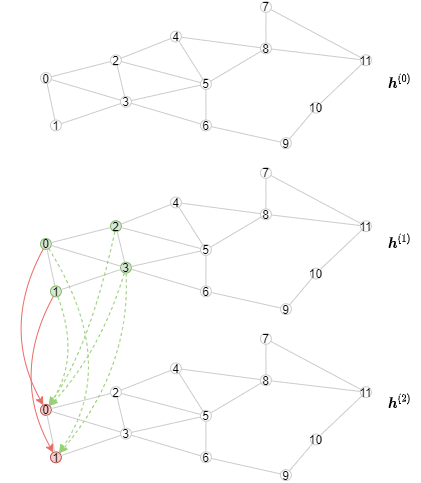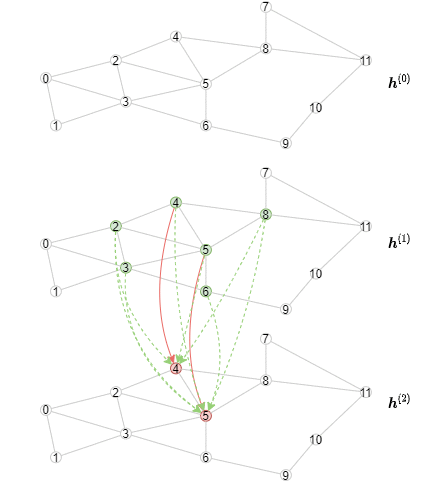
오프라인 추론 구현하기¶
6.1 모델을 미니-배치 학습에 맞게 만들기 에서 다룬 2-레이어 GCN을 생각해 보자. 오프라인 추론을 구현하는 방법은 여전히 MultiLayerFullNeighborSampler 를 사용하지만, 한번에 하나의 레이어에 대한 샘플링을 수행한다. 하나의 레이어에 대한 계산은 메시지들어 어떻게 aggregate되고 합쳐지는지에 의존하기 때문에 오프라인 추론은 GNN 모듈의 메소드로 구현된다는 점을 주목하자.
class StochasticTwoLayerGCN(nn.Module):
def __init__(self, in_features, hidden_features, out_features):
super().__init__()
self.hidden_features = hidden_features
self.out_features = out_features
self.conv1 = dgl.nn.GraphConv(in_features, hidden_features)
self.conv2 = dgl.nn.GraphConv(hidden_features, out_features)
self.n_layers = 2
def forward(self, blocks, x):
x_dst = x[:blocks[0].number_of_dst_nodes()]
x = F.relu(self.conv1(blocks[0], (x, x_dst)))
x_dst = x[:blocks[1].number_of_dst_nodes()]
x = F.relu(self.conv2(blocks[1], (x, x_dst)))
return x
def inference(self, g, x, batch_size, device):
"""
Offline inference with this module
"""
# Compute representations layer by layer
for l, layer in enumerate([self.conv1, self.conv2]):
y = torch.zeros(g.num_nodes(),
self.hidden_features
if l != self.n_layers - 1
else self.out_features)
sampler = dgl.dataloading.MultiLayerFullNeighborSampler(1)
dataloader = dgl.dataloading.NodeDataLoader(
g, torch.arange(g.num_nodes()), sampler,
batch_size=batch_size,
shuffle=True,
drop_last=False)
# Within a layer, iterate over nodes in batches
for input_nodes, output_nodes, blocks in dataloader:
block = blocks[0]
# Copy the features of necessary input nodes to GPU
h = x[input_nodes].to(device)
# Compute output. Note that this computation is the same
# but only for a single layer.
h_dst = h[:block.number_of_dst_nodes()]
h = F.relu(layer(block, (h, h_dst)))
# Copy to output back to CPU.
y[output_nodes] = h.cpu()
x = y
return y
모델 선택을 위해서 검증 데이터셋에 평가 metric을 계산하는 목적으로 정확한 오프라인 추론을 계산할 필요가 없다는 점을 주목하자. 모든 레이어에 대해서 모든 노드들의 representation을 계산하는 것이 필요한데, 이것은 레이블이 없는 데이터가 많은 semi-supervised 영역에서는 아주 많은 리소스를 필요로하기 때문이다. 이웃 샘플링은 모델 선택 및 평가 목적으로는 충분하다.