Note
Click here to download the full example code
Training GNN with Neighbor Sampling for Node Classification¶
This tutorial shows how to train a multi-layer GraphSAGE for node
classification on ogbn-arxiv provided by Open Graph
Benchmark (OGB). The dataset contains around
170 thousand nodes and 1 million edges.
By the end of this tutorial, you will be able to
Train a GNN model for node classification on a single GPU with DGL’s neighbor sampling components.
This tutorial assumes that you have read the Introduction of Neighbor Sampling for GNN Training.
Loading Dataset¶
OGB already prepared the data as DGL graph.
import os
os.environ["DGLBACKEND"] = "pytorch"
import dgl
import numpy as np
import torch
from ogb.nodeproppred import DglNodePropPredDataset
dataset = DglNodePropPredDataset("ogbn-arxiv")
device = "cpu" # change to 'cuda' for GPU
Out:
WARNING:root:The OGB package is out of date. Your version is 1.2.4, while the latest version is 1.3.6.
Downloading https://snap.stanford.edu/ogb/data/nodeproppred/arxiv.zip
0%| | 0/81 [00:00<?, ?it/s]
Downloaded 0.00 GB: 0%| | 0/81 [00:00<?, ?it/s]
Downloaded 0.00 GB: 1%|1 | 1/81 [00:00<00:21, 3.81it/s]
Downloaded 0.00 GB: 1%|1 | 1/81 [00:00<00:21, 3.81it/s]
Downloaded 0.00 GB: 1%|1 | 1/81 [00:00<00:21, 3.81it/s]
Downloaded 0.00 GB: 1%|1 | 1/81 [00:00<00:21, 3.81it/s]
Downloaded 0.00 GB: 5%|4 | 4/81 [00:00<00:06, 12.11it/s]
Downloaded 0.00 GB: 5%|4 | 4/81 [00:00<00:06, 12.11it/s]
Downloaded 0.01 GB: 5%|4 | 4/81 [00:00<00:06, 12.11it/s]
Downloaded 0.01 GB: 5%|4 | 4/81 [00:00<00:06, 12.11it/s]
Downloaded 0.01 GB: 5%|4 | 4/81 [00:00<00:06, 12.11it/s]
Downloaded 0.01 GB: 5%|4 | 4/81 [00:00<00:06, 12.11it/s]
Downloaded 0.01 GB: 11%|#1 | 9/81 [00:00<00:03, 24.00it/s]
Downloaded 0.01 GB: 11%|#1 | 9/81 [00:00<00:03, 24.00it/s]
Downloaded 0.01 GB: 11%|#1 | 9/81 [00:00<00:03, 24.00it/s]
Downloaded 0.01 GB: 11%|#1 | 9/81 [00:00<00:03, 24.00it/s]
Downloaded 0.01 GB: 11%|#1 | 9/81 [00:00<00:03, 24.00it/s]
Downloaded 0.01 GB: 11%|#1 | 9/81 [00:00<00:03, 24.00it/s]
Downloaded 0.01 GB: 17%|#7 | 14/81 [00:00<00:02, 30.39it/s]
Downloaded 0.01 GB: 17%|#7 | 14/81 [00:00<00:02, 30.39it/s]
Downloaded 0.02 GB: 17%|#7 | 14/81 [00:00<00:02, 30.39it/s]
Downloaded 0.02 GB: 17%|#7 | 14/81 [00:00<00:02, 30.39it/s]
Downloaded 0.02 GB: 17%|#7 | 14/81 [00:00<00:02, 30.39it/s]
Downloaded 0.02 GB: 17%|#7 | 14/81 [00:00<00:02, 30.39it/s]
Downloaded 0.02 GB: 23%|##3 | 19/81 [00:00<00:01, 34.67it/s]
Downloaded 0.02 GB: 23%|##3 | 19/81 [00:00<00:01, 34.67it/s]
Downloaded 0.02 GB: 23%|##3 | 19/81 [00:00<00:01, 34.67it/s]
Downloaded 0.02 GB: 23%|##3 | 19/81 [00:00<00:01, 34.67it/s]
Downloaded 0.02 GB: 23%|##3 | 19/81 [00:00<00:01, 34.67it/s]
Downloaded 0.02 GB: 23%|##3 | 19/81 [00:00<00:01, 34.67it/s]
Downloaded 0.02 GB: 30%|##9 | 24/81 [00:00<00:01, 36.74it/s]
Downloaded 0.02 GB: 30%|##9 | 24/81 [00:00<00:01, 36.74it/s]
Downloaded 0.03 GB: 30%|##9 | 24/81 [00:00<00:01, 36.74it/s]
Downloaded 0.03 GB: 30%|##9 | 24/81 [00:00<00:01, 36.74it/s]
Downloaded 0.03 GB: 30%|##9 | 24/81 [00:00<00:01, 36.74it/s]
Downloaded 0.03 GB: 30%|##9 | 24/81 [00:00<00:01, 36.74it/s]
Downloaded 0.03 GB: 36%|###5 | 29/81 [00:00<00:01, 38.51it/s]
Downloaded 0.03 GB: 36%|###5 | 29/81 [00:00<00:01, 38.51it/s]
Downloaded 0.03 GB: 36%|###5 | 29/81 [00:01<00:01, 38.51it/s]
Downloaded 0.03 GB: 36%|###5 | 29/81 [00:01<00:01, 38.51it/s]
Downloaded 0.03 GB: 36%|###5 | 29/81 [00:01<00:01, 38.51it/s]
Downloaded 0.03 GB: 36%|###5 | 29/81 [00:01<00:01, 38.51it/s]
Downloaded 0.03 GB: 42%|####1 | 34/81 [00:01<00:01, 39.83it/s]
Downloaded 0.03 GB: 42%|####1 | 34/81 [00:01<00:01, 39.83it/s]
Downloaded 0.04 GB: 42%|####1 | 34/81 [00:01<00:01, 39.83it/s]
Downloaded 0.04 GB: 42%|####1 | 34/81 [00:01<00:01, 39.83it/s]
Downloaded 0.04 GB: 42%|####1 | 34/81 [00:01<00:01, 39.83it/s]
Downloaded 0.04 GB: 42%|####1 | 34/81 [00:01<00:01, 39.83it/s]
Downloaded 0.04 GB: 48%|####8 | 39/81 [00:01<00:01, 40.85it/s]
Downloaded 0.04 GB: 48%|####8 | 39/81 [00:01<00:01, 40.85it/s]
Downloaded 0.04 GB: 48%|####8 | 39/81 [00:01<00:01, 40.85it/s]
Downloaded 0.04 GB: 48%|####8 | 39/81 [00:01<00:01, 40.85it/s]
Downloaded 0.04 GB: 48%|####8 | 39/81 [00:01<00:01, 40.85it/s]
Downloaded 0.04 GB: 48%|####8 | 39/81 [00:01<00:01, 40.85it/s]
Downloaded 0.04 GB: 54%|#####4 | 44/81 [00:01<00:00, 40.34it/s]
Downloaded 0.04 GB: 54%|#####4 | 44/81 [00:01<00:00, 40.34it/s]
Downloaded 0.04 GB: 54%|#####4 | 44/81 [00:01<00:00, 40.34it/s]
Downloaded 0.05 GB: 54%|#####4 | 44/81 [00:01<00:00, 40.34it/s]
Downloaded 0.05 GB: 54%|#####4 | 44/81 [00:01<00:00, 40.34it/s]
Downloaded 0.05 GB: 54%|#####4 | 44/81 [00:01<00:00, 40.34it/s]
Downloaded 0.05 GB: 60%|###### | 49/81 [00:01<00:00, 41.19it/s]
Downloaded 0.05 GB: 60%|###### | 49/81 [00:01<00:00, 41.19it/s]
Downloaded 0.05 GB: 60%|###### | 49/81 [00:01<00:00, 41.19it/s]
Downloaded 0.05 GB: 60%|###### | 49/81 [00:01<00:00, 41.19it/s]
Downloaded 0.05 GB: 60%|###### | 49/81 [00:01<00:00, 41.19it/s]
Downloaded 0.05 GB: 60%|###### | 49/81 [00:01<00:00, 41.19it/s]
Downloaded 0.05 GB: 67%|######6 | 54/81 [00:01<00:00, 41.96it/s]
Downloaded 0.05 GB: 67%|######6 | 54/81 [00:01<00:00, 41.96it/s]
Downloaded 0.05 GB: 67%|######6 | 54/81 [00:01<00:00, 41.96it/s]
Downloaded 0.06 GB: 67%|######6 | 54/81 [00:01<00:00, 41.96it/s]
Downloaded 0.06 GB: 67%|######6 | 54/81 [00:01<00:00, 41.96it/s]
Downloaded 0.06 GB: 67%|######6 | 54/81 [00:01<00:00, 41.96it/s]
Downloaded 0.06 GB: 73%|#######2 | 59/81 [00:01<00:00, 42.04it/s]
Downloaded 0.06 GB: 73%|#######2 | 59/81 [00:01<00:00, 42.04it/s]
Downloaded 0.06 GB: 73%|#######2 | 59/81 [00:01<00:00, 42.04it/s]
Downloaded 0.06 GB: 73%|#######2 | 59/81 [00:01<00:00, 42.04it/s]
Downloaded 0.06 GB: 73%|#######2 | 59/81 [00:01<00:00, 42.04it/s]
Downloaded 0.06 GB: 73%|#######2 | 59/81 [00:01<00:00, 42.04it/s]
Downloaded 0.06 GB: 79%|#######9 | 64/81 [00:01<00:00, 42.51it/s]
Downloaded 0.06 GB: 79%|#######9 | 64/81 [00:01<00:00, 42.51it/s]
Downloaded 0.06 GB: 79%|#######9 | 64/81 [00:01<00:00, 42.51it/s]
Downloaded 0.07 GB: 79%|#######9 | 64/81 [00:01<00:00, 42.51it/s]
Downloaded 0.07 GB: 79%|#######9 | 64/81 [00:01<00:00, 42.51it/s]
Downloaded 0.07 GB: 79%|#######9 | 64/81 [00:01<00:00, 42.51it/s]
Downloaded 0.07 GB: 85%|########5 | 69/81 [00:01<00:00, 42.89it/s]
Downloaded 0.07 GB: 85%|########5 | 69/81 [00:01<00:00, 42.89it/s]
Downloaded 0.07 GB: 85%|########5 | 69/81 [00:01<00:00, 42.89it/s]
Downloaded 0.07 GB: 85%|########5 | 69/81 [00:01<00:00, 42.89it/s]
Downloaded 0.07 GB: 85%|########5 | 69/81 [00:01<00:00, 42.89it/s]
Downloaded 0.07 GB: 85%|########5 | 69/81 [00:02<00:00, 42.89it/s]
Downloaded 0.07 GB: 91%|#########1| 74/81 [00:02<00:00, 41.36it/s]
Downloaded 0.07 GB: 91%|#########1| 74/81 [00:02<00:00, 41.36it/s]
Downloaded 0.07 GB: 91%|#########1| 74/81 [00:02<00:00, 41.36it/s]
Downloaded 0.08 GB: 91%|#########1| 74/81 [00:02<00:00, 41.36it/s]
Downloaded 0.08 GB: 91%|#########1| 74/81 [00:02<00:00, 41.36it/s]
Downloaded 0.08 GB: 91%|#########1| 74/81 [00:02<00:00, 41.36it/s]
Downloaded 0.08 GB: 98%|#########7| 79/81 [00:02<00:00, 42.00it/s]
Downloaded 0.08 GB: 98%|#########7| 79/81 [00:02<00:00, 42.00it/s]
Downloaded 0.08 GB: 98%|#########7| 79/81 [00:02<00:00, 42.00it/s]
Downloaded 0.08 GB: 100%|##########| 81/81 [00:02<00:00, 37.72it/s]
Extracting dataset/arxiv.zip
Loading necessary files...
This might take a while.
Processing graphs...
0%| | 0/1 [00:00<?, ?it/s]
100%|##########| 1/1 [00:00<00:00, 21845.33it/s]
Converting graphs into DGL objects...
0%| | 0/1 [00:00<?, ?it/s]
100%|##########| 1/1 [00:00<00:00, 267.36it/s]
Saving...
OGB dataset is a collection of graphs and their labels. ogbn-arxiv
dataset only contains a single graph. So you can
simply get the graph and its node labels like this:
graph, node_labels = dataset[0]
# Add reverse edges since ogbn-arxiv is unidirectional.
graph = dgl.add_reverse_edges(graph)
graph.ndata["label"] = node_labels[:, 0]
print(graph)
print(node_labels)
node_features = graph.ndata["feat"]
num_features = node_features.shape[1]
num_classes = (node_labels.max() + 1).item()
print("Number of classes:", num_classes)
Out:
Graph(num_nodes=169343, num_edges=2332486,
ndata_schemes={'year': Scheme(shape=(1,), dtype=torch.int64), 'feat': Scheme(shape=(128,), dtype=torch.float32), 'label': Scheme(shape=(), dtype=torch.int64)}
edata_schemes={})
tensor([[ 4],
[ 5],
[28],
...,
[10],
[ 4],
[ 1]])
Number of classes: 40
You can get the training-validation-test split of the nodes with
get_split_idx method.
How DGL Handles Computation Dependency¶
In the previous tutorial, you have seen that the computation dependency for message passing of a single node can be described as a series of message flow graphs (MFG).
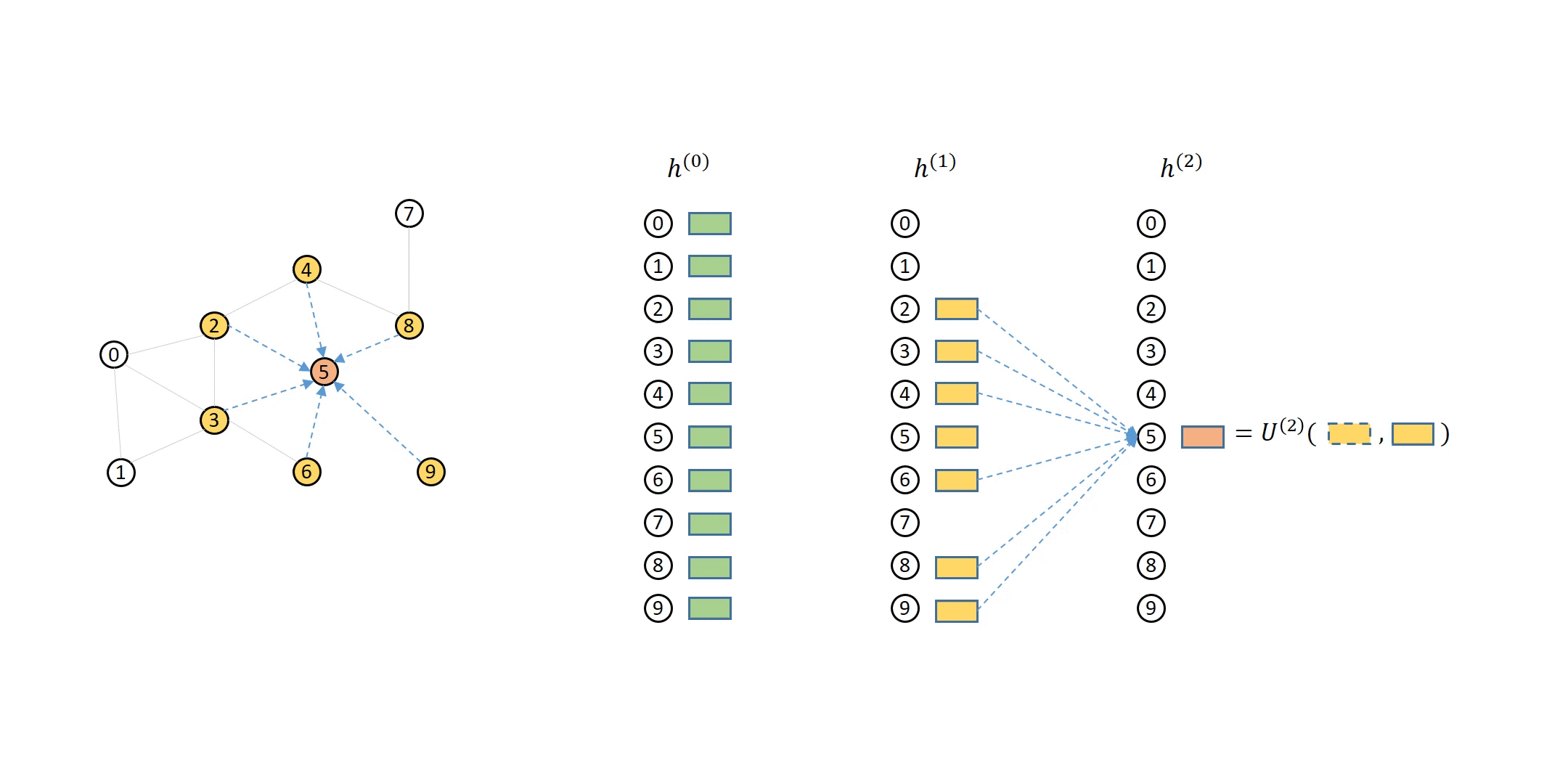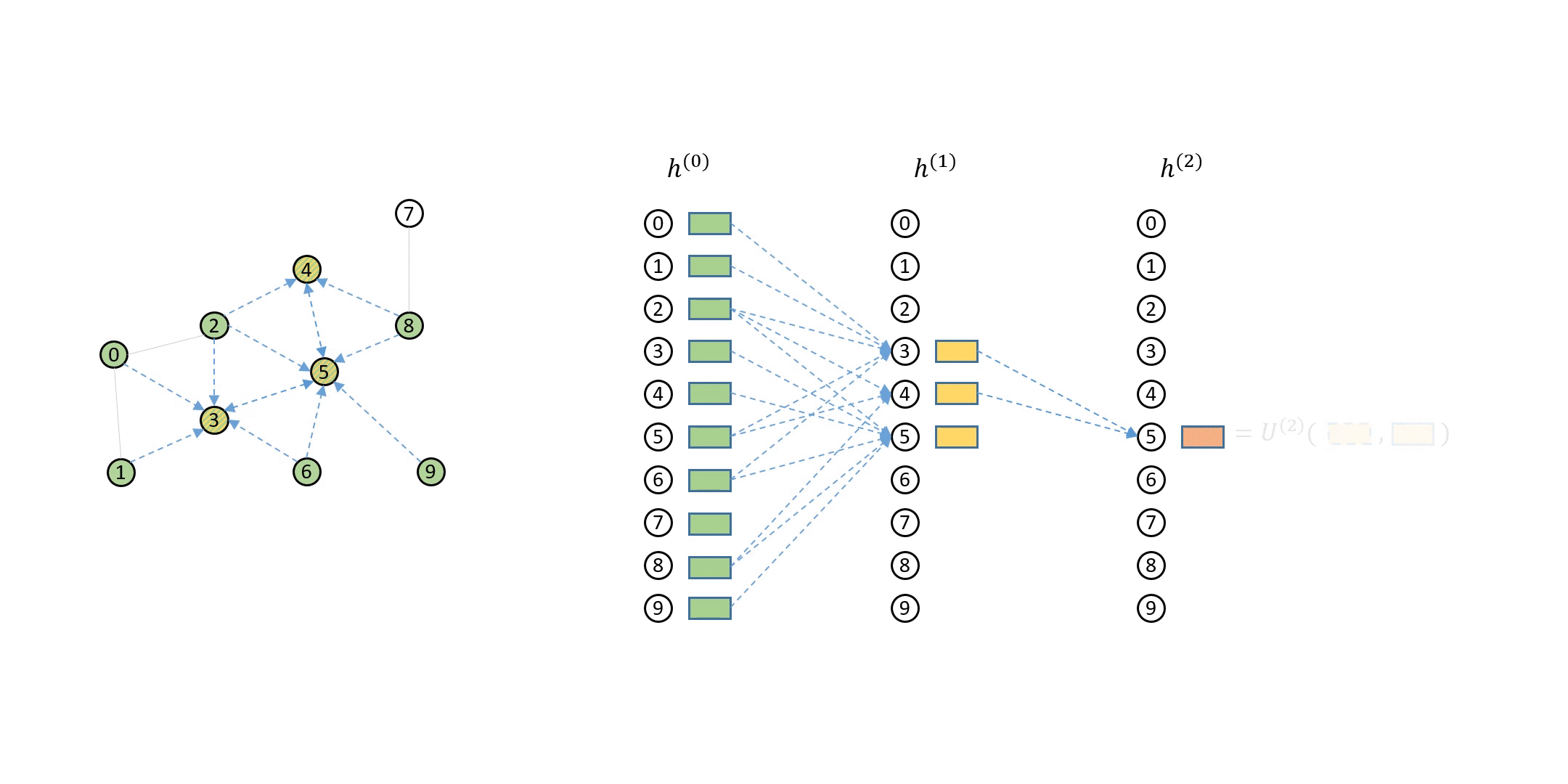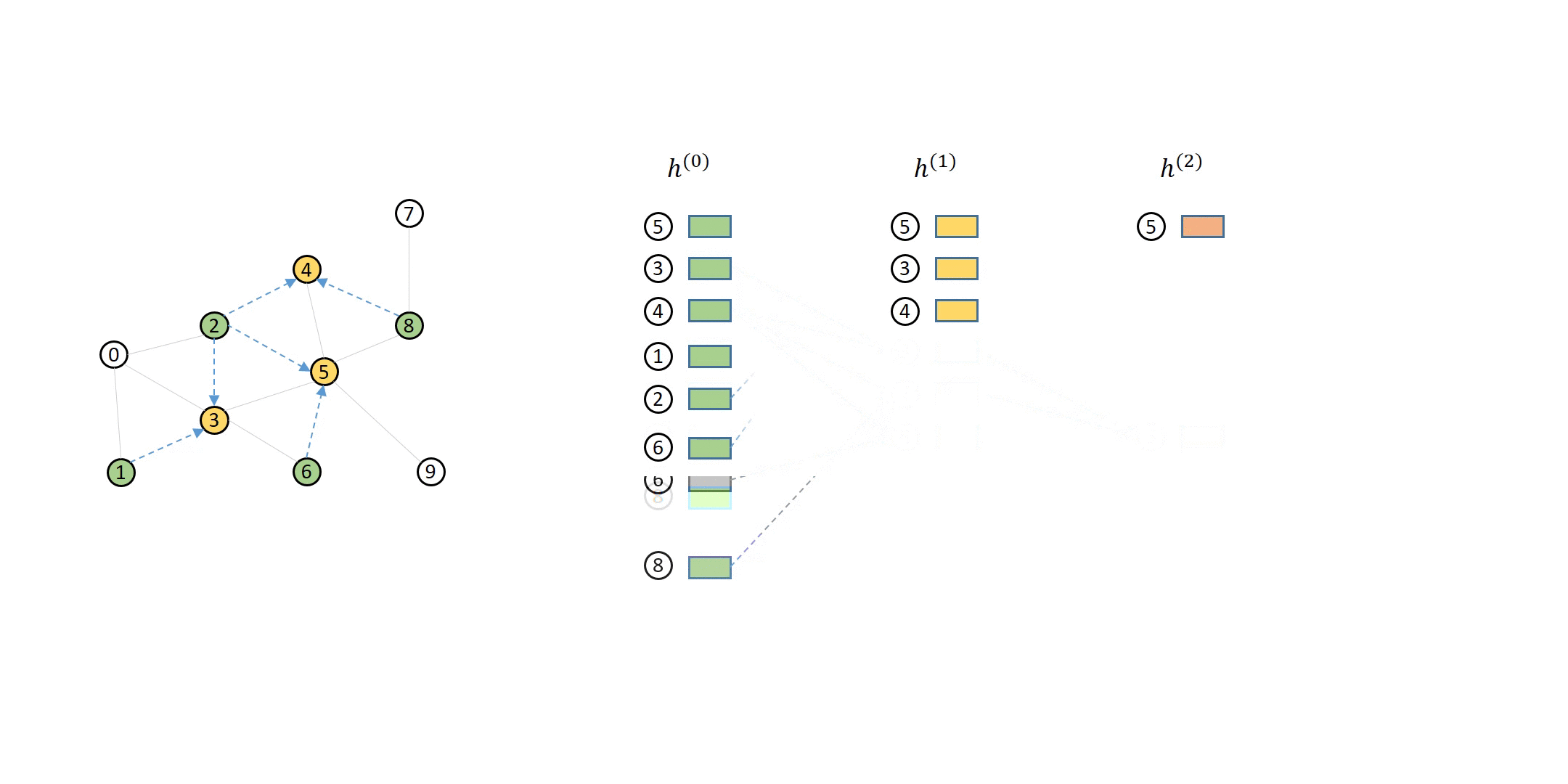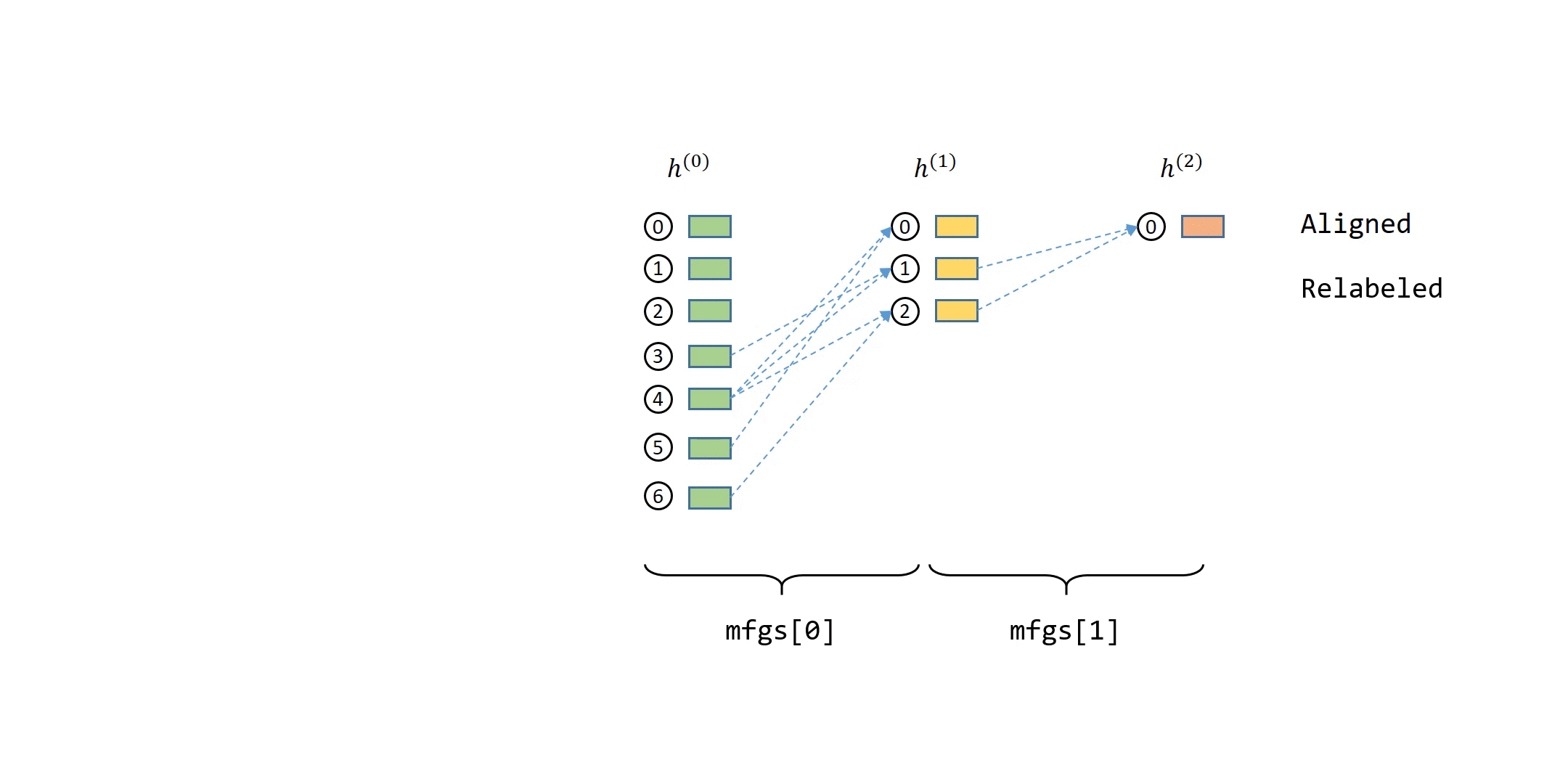
Defining Neighbor Sampler and Data Loader in DGL¶
DGL provides tools to iterate over the dataset in minibatches
while generating the computation dependencies to compute their outputs
with the MFGs above. For node classification, you can use
dgl.dataloading.DataLoader for iterating over the dataset.
It accepts a sampler object to control how to generate the computation
dependencies in the form of MFGs. DGL provides
implementations of common sampling algorithms such as
dgl.dataloading.NeighborSampler which randomly picks
a fixed number of neighbors for each node.
Note
To write your own neighbor sampler, please refer to this user guide section.
The syntax of dgl.dataloading.DataLoader is mostly similar to a
PyTorch DataLoader, with the addition that it needs a graph to
generate computation dependency from, a set of node IDs to iterate on,
and the neighbor sampler you defined.
Let’s say that each node will gather messages from 4 neighbors on each layer. The code defining the data loader and neighbor sampler will look like the following.
sampler = dgl.dataloading.NeighborSampler([4, 4])
train_dataloader = dgl.dataloading.DataLoader(
# The following arguments are specific to DGL's DataLoader.
graph, # The graph
train_nids, # The node IDs to iterate over in minibatches
sampler, # The neighbor sampler
device=device, # Put the sampled MFGs on CPU or GPU
# The following arguments are inherited from PyTorch DataLoader.
batch_size=1024, # Batch size
shuffle=True, # Whether to shuffle the nodes for every epoch
drop_last=False, # Whether to drop the last incomplete batch
num_workers=0, # Number of sampler processes
)
Note
Since DGL 0.7 neighborhood sampling on GPU is supported. Please refer to 6.7 Using GPU for Neighborhood Sampling if you are interested.
You can iterate over the data loader and see what it yields.
input_nodes, output_nodes, mfgs = example_minibatch = next(
iter(train_dataloader)
)
print(example_minibatch)
print(
"To compute {} nodes' outputs, we need {} nodes' input features".format(
len(output_nodes), len(input_nodes)
)
)
Out:
/home/ubuntu/prod-doc/readthedocs.org/user_builds/dgl/checkouts/1.1.x/python/dgl/dataloading/dataloader.py:1150: DGLWarning: Dataloader CPU affinity opt is not enabled, consider switching it on (see enable_cpu_affinity() or CPU best practices for DGL [https://docs.dgl.ai/tutorials/cpu/cpu_best_practises.html])
f"Dataloader CPU affinity opt is not enabled, consider switching it on "
[tensor([129178, 22172, 40037, ..., 144920, 19026, 53154]), tensor([129178, 22172, 40037, ..., 123317, 164528, 80388]), [Block(num_src_nodes=12942, num_dst_nodes=4120, num_edges=15002), Block(num_src_nodes=4120, num_dst_nodes=1024, num_edges=3316)]]
To compute 1024 nodes' outputs, we need 12942 nodes' input features
DGL’s DataLoader gives us three items per iteration.
An ID tensor for the input nodes, i.e., nodes whose input features are needed on the first GNN layer for this minibatch.
An ID tensor for the output nodes, i.e. nodes whose representations are to be computed.
A list of MFGs storing the computation dependencies for each GNN layer.
You can get the source and destination node IDs of the MFGs and verify that the first few source nodes are always the same as the destination nodes. As we described in the overview, destination nodes’ own features from the previous layer may also be necessary in the computation of the new features.
Out:
tensor([129178, 22172, 40037, ..., 144920, 19026, 53154])
tensor([129178, 22172, 40037, ..., 120806, 95027, 18066])
True
Defining Model¶
Let’s consider training a 2-layer GraphSAGE with neighbor sampling. The model can be written as follows:
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn import SAGEConv
class Model(nn.Module):
def __init__(self, in_feats, h_feats, num_classes):
super(Model, self).__init__()
self.conv1 = SAGEConv(in_feats, h_feats, aggregator_type="mean")
self.conv2 = SAGEConv(h_feats, num_classes, aggregator_type="mean")
self.h_feats = h_feats
def forward(self, mfgs, x):
# Lines that are changed are marked with an arrow: "<---"
h_dst = x[: mfgs[0].num_dst_nodes()] # <---
h = self.conv1(mfgs[0], (x, h_dst)) # <---
h = F.relu(h)
h_dst = h[: mfgs[1].num_dst_nodes()] # <---
h = self.conv2(mfgs[1], (h, h_dst)) # <---
return h
model = Model(num_features, 128, num_classes).to(device)
If you compare against the code in the introduction, you will notice several differences:
DGL GNN layers on MFGs. Instead of computing on the full graph:
h = self.conv1(g, x)
you only compute on the sampled MFG:
h = self.conv1(mfgs[0], (x, h_dst))
All DGL’s GNN modules support message passing on MFGs, where you supply a pair of features, one for source nodes and another for destination nodes.
Feature slicing for self-dependency. There are statements that perform slicing to obtain the previous-layer representation of the
nodes:
h_dst = x[:mfgs[0].num_dst_nodes()]
num_dst_nodesmethod works with MFGs, where it will return the number of destination nodes.Since the first few source nodes of the yielded MFG are always the same as the destination nodes, these statements obtain the representations of the destination nodes on the previous layer. They are then combined with neighbor aggregation in
dgl.nn.SAGEConvlayer.
Note
See the custom message passing
tutorial for more details on how to
manipulate MFGs produced in this way, such as the usage
of num_dst_nodes.
Defining Training Loop¶
The following initializes the model and defines the optimizer.
opt = torch.optim.Adam(model.parameters())
When computing the validation score for model selection, usually you can also do neighbor sampling. To do that, you need to define another data loader.
valid_dataloader = dgl.dataloading.DataLoader(
graph,
valid_nids,
sampler,
batch_size=1024,
shuffle=False,
drop_last=False,
num_workers=0,
device=device,
)
import sklearn.metrics
The following is a training loop that performs validation every epoch. It also saves the model with the best validation accuracy into a file.
import tqdm
best_accuracy = 0
best_model_path = "model.pt"
for epoch in range(10):
model.train()
with tqdm.tqdm(train_dataloader) as tq:
for step, (input_nodes, output_nodes, mfgs) in enumerate(tq):
# feature copy from CPU to GPU takes place here
inputs = mfgs[0].srcdata["feat"]
labels = mfgs[-1].dstdata["label"]
predictions = model(mfgs, inputs)
loss = F.cross_entropy(predictions, labels)
opt.zero_grad()
loss.backward()
opt.step()
accuracy = sklearn.metrics.accuracy_score(
labels.cpu().numpy(),
predictions.argmax(1).detach().cpu().numpy(),
)
tq.set_postfix(
{"loss": "%.03f" % loss.item(), "acc": "%.03f" % accuracy},
refresh=False,
)
model.eval()
predictions = []
labels = []
with tqdm.tqdm(valid_dataloader) as tq, torch.no_grad():
for input_nodes, output_nodes, mfgs in tq:
inputs = mfgs[0].srcdata["feat"]
labels.append(mfgs[-1].dstdata["label"].cpu().numpy())
predictions.append(model(mfgs, inputs).argmax(1).cpu().numpy())
predictions = np.concatenate(predictions)
labels = np.concatenate(labels)
accuracy = sklearn.metrics.accuracy_score(labels, predictions)
print("Epoch {} Validation Accuracy {}".format(epoch, accuracy))
if best_accuracy < accuracy:
best_accuracy = accuracy
torch.save(model.state_dict(), best_model_path)
# Note that this tutorial do not train the whole model to the end.
break
Out:
0%| | 0/89 [00:00<?, ?it/s]
3%|3 | 3/89 [00:00<00:03, 27.10it/s, loss=3.527, acc=0.113]
7%|6 | 6/89 [00:00<00:02, 27.97it/s, loss=3.292, acc=0.177]
10%|# | 9/89 [00:00<00:02, 28.03it/s, loss=3.118, acc=0.176]
13%|#3 | 12/89 [00:00<00:02, 27.61it/s, loss=2.998, acc=0.175]
17%|#6 | 15/89 [00:00<00:02, 27.94it/s, loss=2.877, acc=0.247]
20%|## | 18/89 [00:00<00:02, 28.20it/s, loss=2.801, acc=0.269]
24%|##3 | 21/89 [00:00<00:02, 28.44it/s, loss=2.850, acc=0.266]
27%|##6 | 24/89 [00:00<00:02, 28.35it/s, loss=2.739, acc=0.299]
30%|### | 27/89 [00:00<00:02, 28.43it/s, loss=2.559, acc=0.334]
34%|###3 | 30/89 [00:01<00:02, 28.47it/s, loss=2.530, acc=0.313]
37%|###7 | 33/89 [00:01<00:01, 28.50it/s, loss=2.503, acc=0.339]
40%|#### | 36/89 [00:01<00:01, 27.95it/s, loss=2.419, acc=0.363]
44%|####3 | 39/89 [00:01<00:01, 28.08it/s, loss=2.433, acc=0.365]
47%|####7 | 42/89 [00:01<00:01, 28.25it/s, loss=2.385, acc=0.375]
51%|##### | 45/89 [00:01<00:01, 28.41it/s, loss=2.262, acc=0.410]
54%|#####3 | 48/89 [00:01<00:01, 28.48it/s, loss=2.258, acc=0.427]
57%|#####7 | 51/89 [00:01<00:01, 28.49it/s, loss=2.171, acc=0.456]
61%|###### | 54/89 [00:01<00:01, 28.47it/s, loss=2.199, acc=0.422]
64%|######4 | 57/89 [00:02<00:01, 28.57it/s, loss=2.037, acc=0.512]
67%|######7 | 60/89 [00:02<00:01, 28.53it/s, loss=2.120, acc=0.451]
71%|####### | 63/89 [00:02<00:00, 28.54it/s, loss=2.001, acc=0.490]
74%|#######4 | 66/89 [00:02<00:00, 28.57it/s, loss=1.925, acc=0.495]
78%|#######7 | 69/89 [00:02<00:00, 28.56it/s, loss=1.950, acc=0.504]
81%|######## | 72/89 [00:02<00:00, 28.57it/s, loss=1.885, acc=0.512]
84%|########4 | 75/89 [00:02<00:00, 28.65it/s, loss=1.938, acc=0.496]
88%|########7 | 78/89 [00:02<00:00, 28.72it/s, loss=1.894, acc=0.515]
91%|#########1| 81/89 [00:02<00:00, 28.69it/s, loss=1.808, acc=0.536]
94%|#########4| 84/89 [00:02<00:00, 28.60it/s, loss=1.823, acc=0.529]
98%|#########7| 87/89 [00:03<00:00, 28.61it/s, loss=1.761, acc=0.520]
100%|##########| 89/89 [00:03<00:00, 28.45it/s, loss=1.645, acc=0.531]
0%| | 0/30 [00:00<?, ?it/s]
20%|## | 6/30 [00:00<00:00, 50.37it/s]
40%|#### | 12/30 [00:00<00:00, 50.66it/s]
60%|###### | 18/30 [00:00<00:00, 50.67it/s]
80%|######## | 24/30 [00:00<00:00, 50.44it/s]
100%|##########| 30/30 [00:00<00:00, 51.87it/s]
100%|##########| 30/30 [00:00<00:00, 51.23it/s]
Epoch 0 Validation Accuracy 0.5524010872848082
Conclusion¶
In this tutorial, you have learned how to train a multi-layer GraphSAGE with neighbor sampling.
What’s next?¶
During inference you may wish to disable neighbor sampling. If so, please refer to the user guide on exact offline inference.
# Thumbnail credits: Stanford CS224W Notes
# sphinx_gallery_thumbnail_path = '_static/blitz_1_introduction.png'
Total running time of the script: ( 0 minutes 11.363 seconds)